
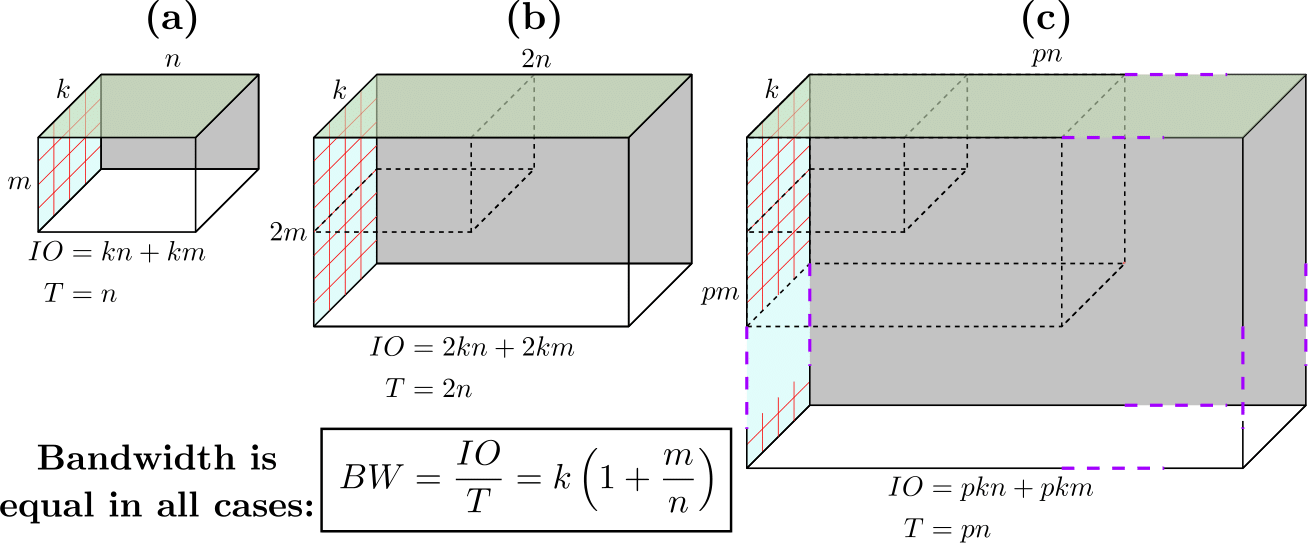
We offer a novel approach to matrix-matrix multiplication computation on computing platforms with memory hierarchies. Constant-bandwidth (CB) blocks improve computation throughput for architectures limited by external memory bandwidth. Configuring the shape and size of CB blocks operating from within any memory hierarchy level (e.g., internal SRAM), we achieve high throughput while holding external bandwidth (e.g., with DRAM) constant. We explain how, surprisingly, CB blocks can maintain constant external bandwidth as computation throughput increases. Analogous to partitioning a cake into pieces, we dub our CB-partitioned system CAKE. We show CAKE outperforms state-of-the-art libraries in computation time on real-world systems (e.g. ARMPL library for ARM CPUs) where external bandwidth represents a bottleneck, demonstrating CAKE's ability to address the memory wall. CAKE achieves superior performance by directly using theoretically optimal CB-partitioned blocks in tiling and scheduling, obviating the need for extensive design search.
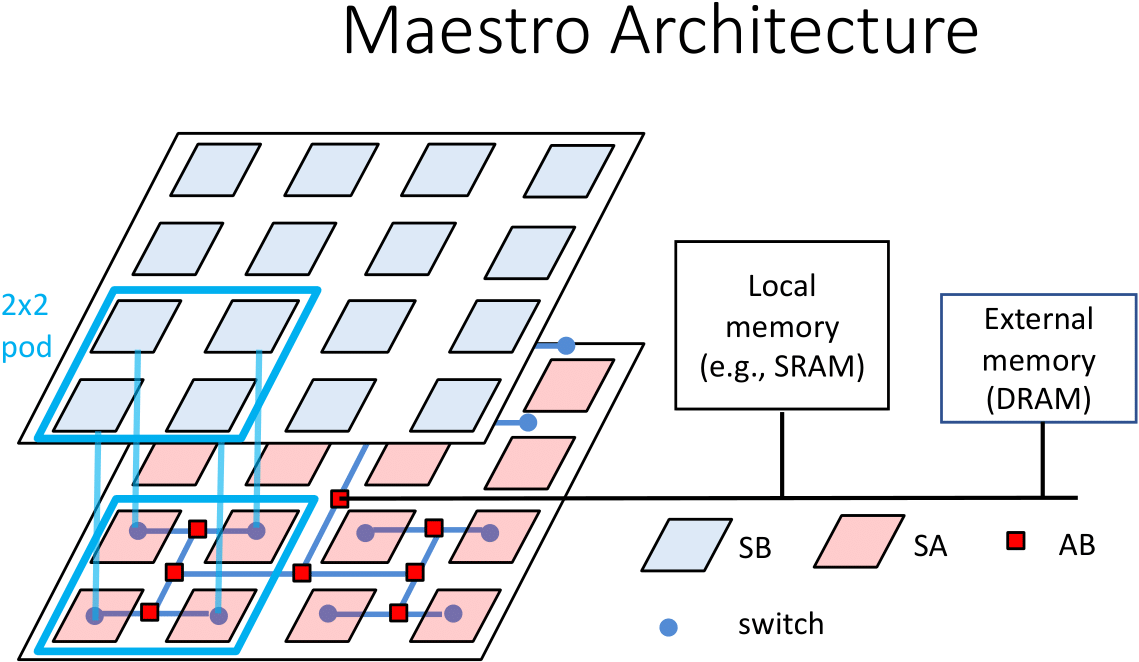
Before applying CAKE to CPUs, we validated CAKE schedules on Maestro, a memory-on-logic 3D IC abstract architecture for parallel processing with an arbitrary number of systolic arrays. Maestro introduces an on-chip H-tree switching network connecting a layer of memory blocks stacked on top of a layer of logic blocks (systolic arrays). A network of combine blocks handles results from the logic blocks, enabling parallel accumulation. Maestro is a useful model for evaluating architectures with many systolic arrays (e.g., a simplified model of the TPU may be mapped to a Maestro instance). We validate CAKE's CB blocking approach with a simulator built in SystemC using the Nvidia MatchLib connections library. To simplify programming and reduce module complexity, standardized packets are used for all communication between hardware modules (systolic arrays, H-tree switches, etc). Each matrix tile involved in the GEMM computation is encapsulated in a packet containing a header to control routing. Users may use the simulator to answer questions such as how much high-capacity on-chip NVM and 3D IC packaging can help DNN performance as on-chip computing capacity increases.
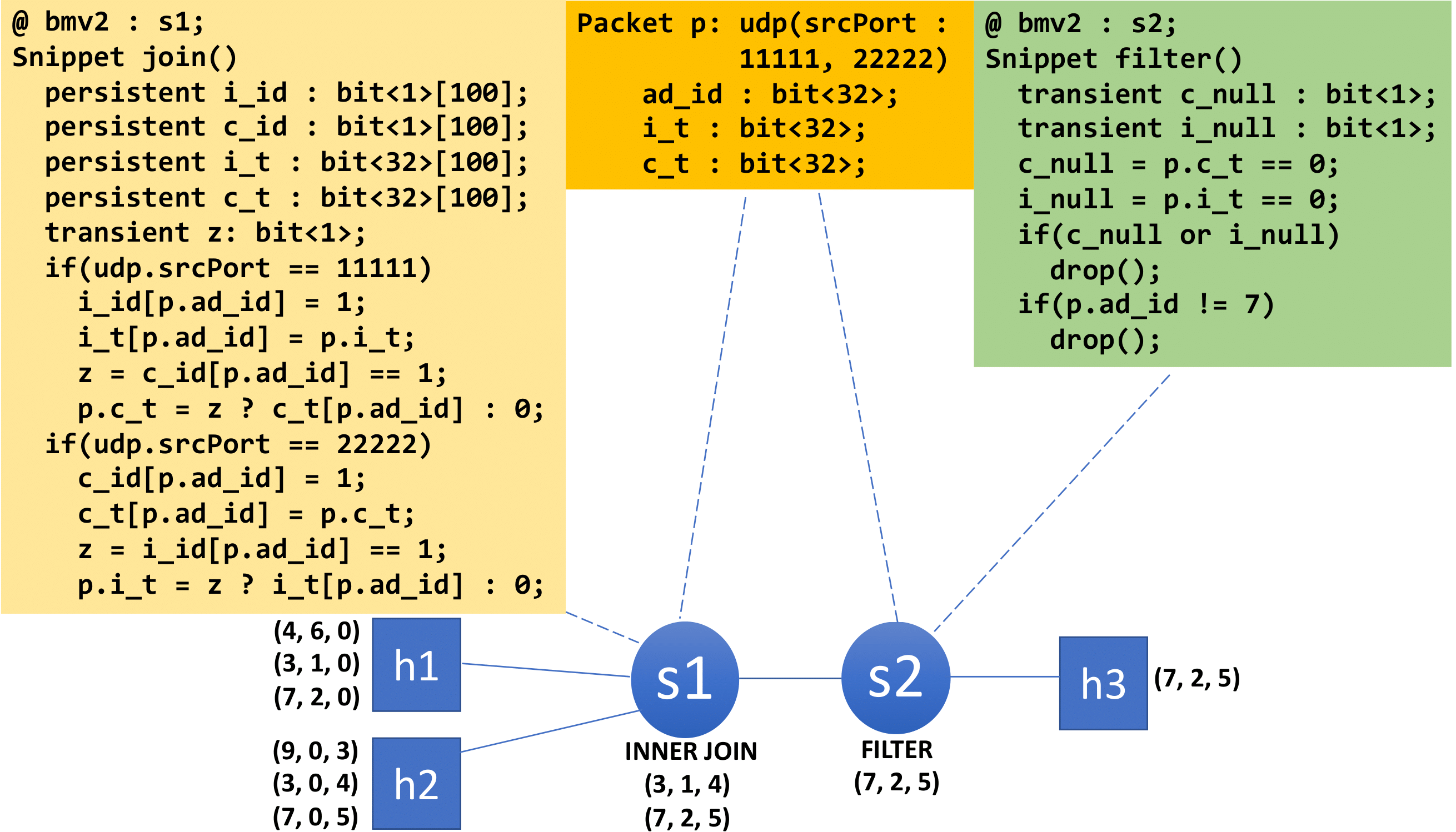
This paper presents Sluice, a programming model that takes a network-wide specification of the data plane and compiles it into runnable code that can be launched directly on the programmable devices of a network. In contrast to prior network-wide programming models like SNAP and Maple that were focused on specific tasks (e.g., routing and security policies), Sluice aims to be more generic, but potentially at the cost of operator effort in specifying code placement. Sluice endows network operators with the ability to design and deploy large network programs for various functions such as scheduling, measurement, and in-network applications. The benefits of Sluice can be summarized as follows: (1) Sluice provides the same functionality as a per-device language like P4 but makes it easier to program the data plane of an entire network by abstracting device-specific architectural details like stateful ALUs, pipelines, etc., and (2) Sluice automatically reduces the amount of boilerplate code needed to write data plane functionality. For instance, the 8 line traffic matrix Sluice program we demonstrate translates into over 40 lines of P4 (excluding header/metadata/parser definitions and ipv4 forwarding P4 code). We demonstrate Sluice’s functionality and ease of use via two examples: traffic matrix generation for network analysis and a streaming join-filter operation. Sluice is open-source and available at https://github.com/sluice-project/sluice.
During the summer of 2018, I developed a system to run SQL-like queries on streams of packets entering a virutal programmable switch. Each stream represents an unbounded table. In addition to standard eth/ip/tcp headers, each packet contains a header representing a row of data made up of fields (column name) and their values. An operator query is run on the virtual switch as a P4-16 program which processes the packet streams and returns the query result. On the left is a demo of a simple JOIN operation between two streams. Host 1 sends a stream of ad impressions while Host 2 sends a stream of ad clicks. The two streams are efficiently joined on the "adId" field at the virtual switch and the query result is sent to Host 3. The MySQL query corresponding to this example is shown below.
SELECT adId, impression_time, click_time
FROM impressions i
INNER JOIN clicks c ON i.adId = c.adId
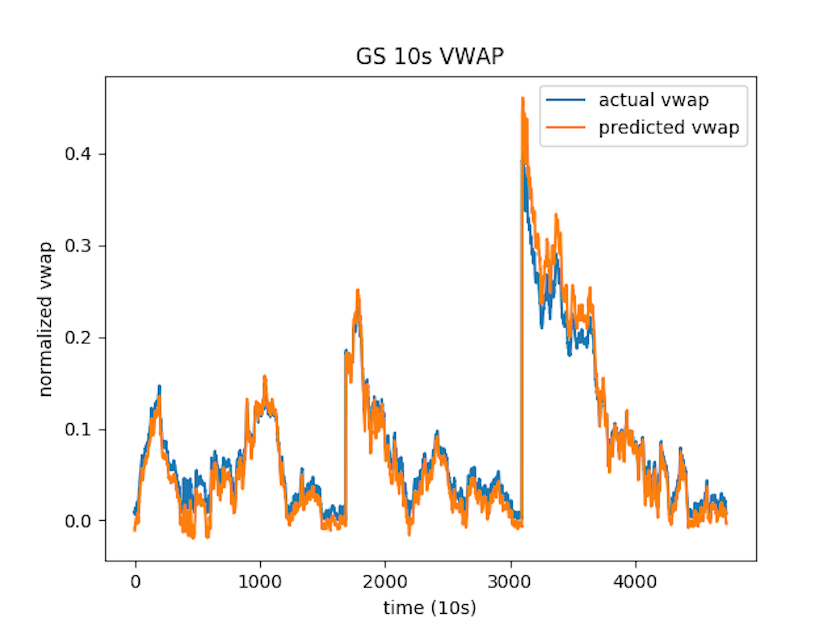
This is a research project where we designed several algorithms for volume-weighted-average-price (VWAP) prediction in equities markets. Our dataset consisted of millisecond-level limit-order books for multiple stocks. Random forest and logistic regression were used for VWAP direction classification (up or down), while PCA and random forest were used for feature selection. Least absolute shrinkage and selection operator (LASSO) regression was performed to predict real VWAP value. We also used a long short-term memory (LSTM) recurrent neural network to predict real VWAP value. To the left is a plot showing real vs. predicted 10-second normalized VWAP time series for Goldman Sachs stock over the time period from 11/05/2018 to 12/04/2018.
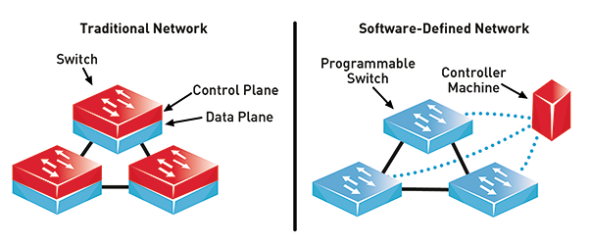
I built a software-defined networking (SDN) application implementing optimal routing using the distance-vector routing algorithm, and load balancing in a mininet network emulator. Communication between hosts, virtual hosts, and switches was tested on several network topologies including mesh, tree, and linear. The floodlight openflow controller was used to add/delete new nodes/links to the network as well as manage real-time changes to the topology.
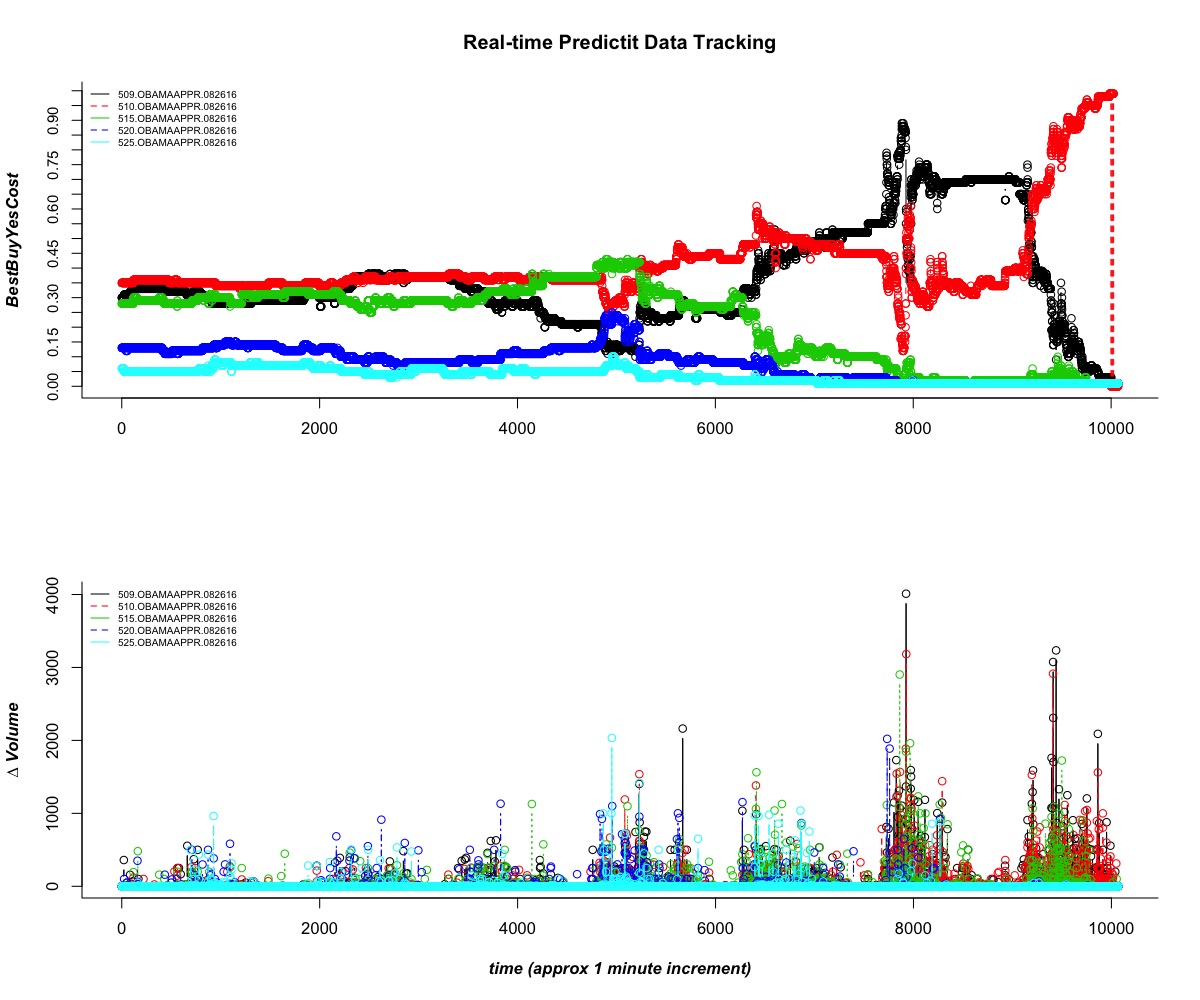
During the months leading up to the 2016 election, I became curious about the effectiveness of political futures markets in predicting political events. In these markets, the price of a candidate reflects their underlying probability of winning and is a value ranging from $0 to $0.99. If the candidate wins, the contract holder earns $1 and realizes a profit. Otherwise the price of the contract goes to $0 and the buyer loses the whole purchase price i.e. the contract is a binary option. I built a software platform that interfaces with online political markets, such as Predictit.org, and allows for automatic trade execution. After collecting and analyzing price, volume, and polling data for several months, I developed quantitative strategies to trade on. I then used my platform to process streams of incoming price/volume data and algorithmically trade based on the detection of real-time signals. A particularly successful strategy centered around momentum trading using higher-order finite difference methods.
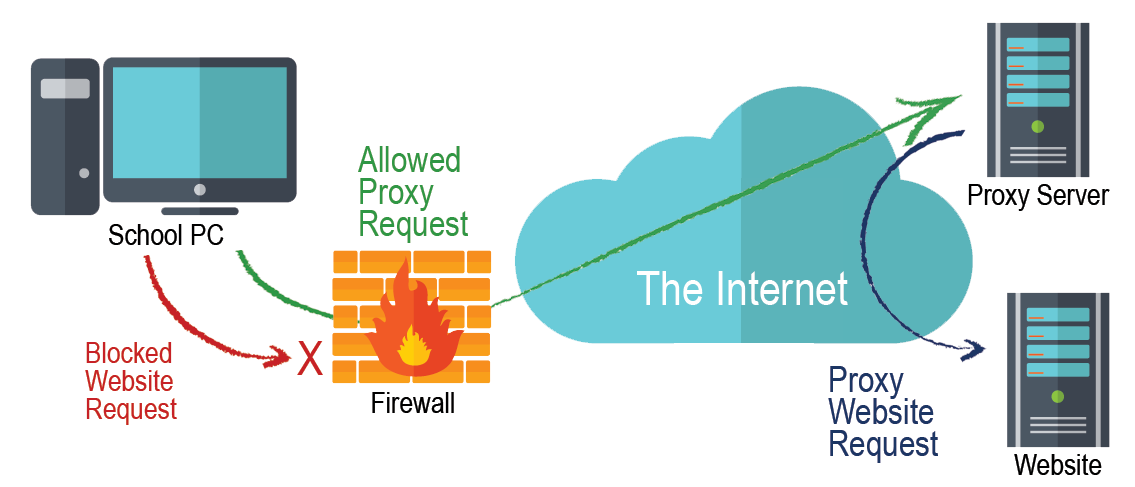
I built a lightweight multi-threaded web proxy server in C. The server can handle up to 100 asynchronous requests. Each client creates a TCP connection to the server and transmits a URL string. The server continuously listens for new clients and launches each one on a separate posix thread (pThread). Each time a new URL is queried by a client, the corresponding HTML document is cached at the server. The next time this same url is queried for, the program simply returns the corresponding HTML from the cache. This eases strain on the network by reducing the number of external requests made by the server. A separate thread performs cache validation to update webpages that may have changed.